The recent paper GRAPHTEXT: Graph Reasoning in Text Space by Jianan Zhao et al. introduces a groundbreaking approach to bridging the gap between large language models (LLMs) and graph machine learning, a domain traditionally dominated by graph neural networks (GNNs). Despite the advancements in LLMs, their application in graph machine learning has been limited. This limitation is largely due to the discrepancy in how LLMs and GNNs process and interpret data, with LLMs excelling in natural language understanding but struggling to natively comprehend graph-structured data.
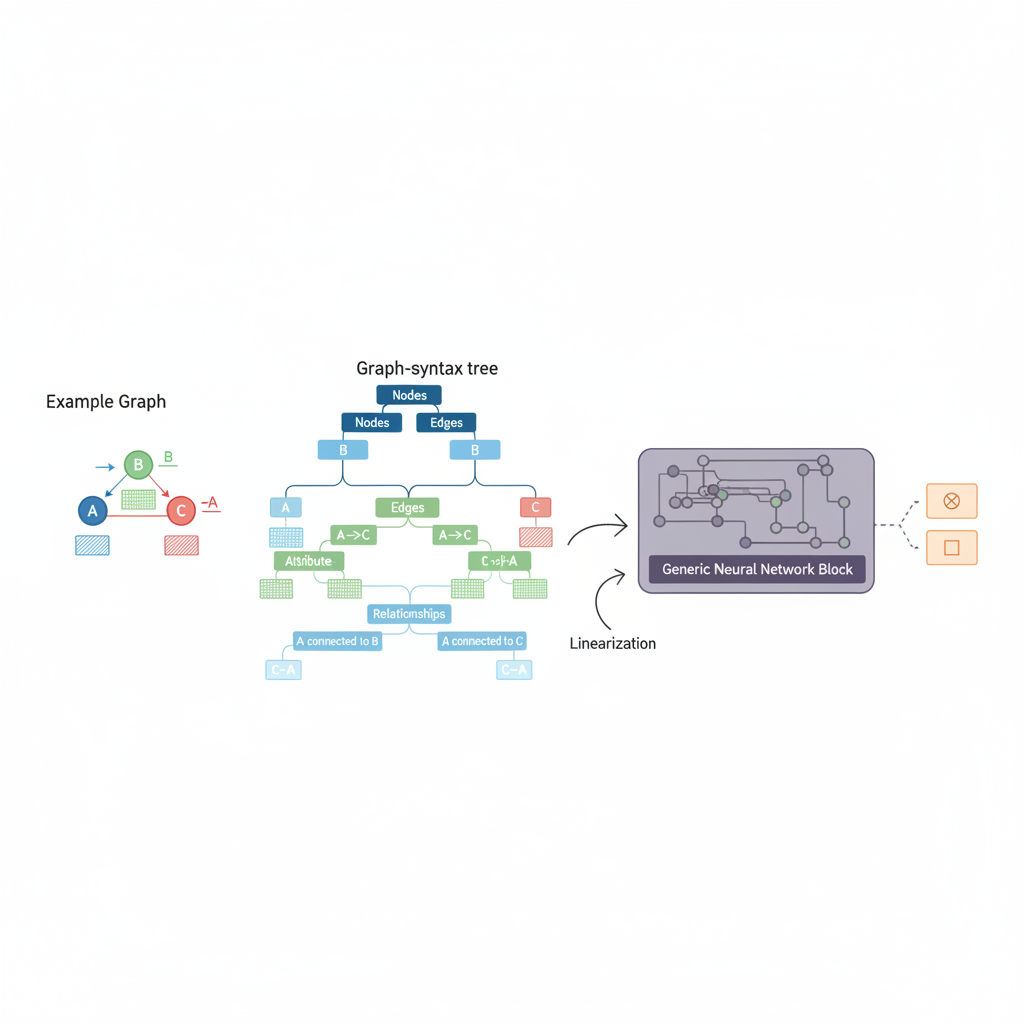
The core innovation of GRAPHTEXT lies in its method of converting graphs into a natural language format via a graph-syntax tree. This transformation allows graph tasks to be reframed as text generation tasks, making them accessible to LLMs without the need for extensive retraining. The graph-syntax tree encodes detailed information about node attributes and relationships, turning the traversal of this tree into a sequential text prompt that LLMs can process.
One of the most significant advantages of GRAPHTEXT is its ability to leverage in-context learning of pre-trained LLMs for graph reasoning tasks, eliminating the need for additional training. This approach contrasts sharply with traditional supervised GNNs, offering a more flexible and intuitive method for graph analysis. By incorporating graph inductive biases directly into the text-based representation, GRAPHTEXT ensures that essential graph properties, such as feature propagation and higher-order structures, are preserved and leveraged during the reasoning process.
The interactive nature of GRAPHTEXT also promotes a collaborative environment where humans and other LLMs can easily inspect, critique, and refine the model’s reasoning. This transparency is not only beneficial for model improvement but also for educational purposes, allowing a broader audience to understand and engage with complex graph reasoning tasks.
Experimental evaluations demonstrate GRAPHTEXT’s effectiveness, with notable performance on node classification benchmarks and favorable comparisons to standard GNN baselines. The utility of synthetic relations and attributes in enhancing model performance was also highlighted. Additionally, the extension of GRAPHTEXT to text-attributed graphs and its compatibility with both open-source and closed-source LLMs, including instruction tuning with models like Llama-2-7B, underscore its versatility and adaptability.
However, the approach is not without its challenges. The discretization of continuous features, the design of graph-syntax trees, and the automation of prompt/structure design remain areas ripe for exploration and improvement. These limitations underline the ongoing need for research and development in making graph reasoning more accessible and effective through language models.
In summary, GRAPHTEXT represents a significant step forward in making graph reasoning tasks more understandable and executable by LLMs. Its innovative methodology, combined with the interactivity and versatility it offers, makes it a promising direction for future research in graph machine learning and natural language processing.



